Covariate Shift(Drift)
우리가 지도학습을 할 때 (무의식적으로?) 하는 중요한 가정 중 하나는, 훈련으로 이용했던 데이터와 테스트 데이터가 같은 분포를 가진다는 점이다. (Empirical Risk Minimization 참고)
즉, 모델이 학습할 때 본 세계와 실제로 적용될 세계가 크게 다르지 않다고 보는 것이다.
하지만 현실에서 AI 모델을 학습하고 시험할 땐 늘 그런 가정을 만족하지는 않는다.
제약 회사 이야기
제약 회사에서 약이 하나 개발되었고 약의 효과를 예측하는데, 한국은 데이터가 부족하여 데이터가 풍부한 미국에서 학습을 했다고 생각해보자.
이 약은 미국인들이 많이 가진 유전자 B와 잘 맞아, 미국의 데이터에서는 약의 효과가 매우 뛰어났다. 제약 회사는 큰 기대를 안고 바로 한국 시장에 진출했다.
그러나 한국인들은 유전자 B를 가진 사람이 많지 않았다. 따라서 약의 효과가 미국에서처럼 좋지 않았고, 결국 실패했다. 물론 한국에서도 유전자 B를 가진 사람들에게는 약이 좋은 효과를 보였을 것이다.
즉 투약자 집단의 특성 분포() 자체가 달라졌기 때문에, 한국에서는 예측과 다른 결과가 나타났다.
따로 AI 모델을 이야기에 넣지는 않았지만, 이것이 Covariate Shift로 인해 예측이 실패한 경우이다.
수식 정리
수식적으로 정리하면 아래와 같다.
입력 변수 의 분포가 학습 도메인과 테스트 도메인에서 달라진다.
하지만
가 주어졌을 때 outcome을 생성하는 메커니즘, 분포는 같다.
예시
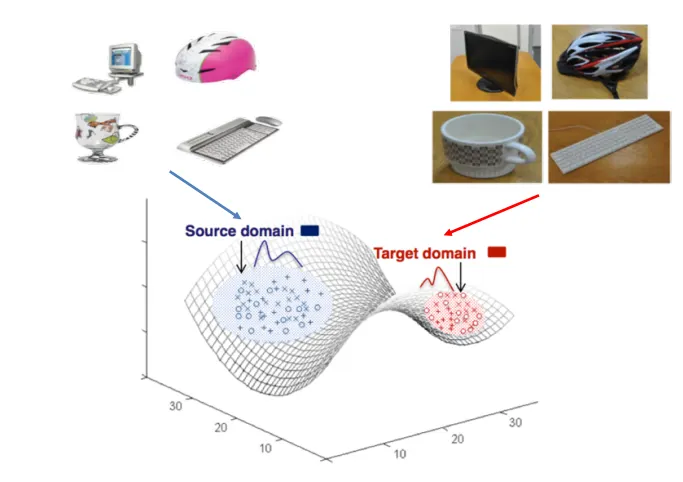
(ECCV 2020 Domain Adaptation for Visual Applications Tutorial)
Source Domain(왼쪽)은 주로 배경이 하얀 깔끔한 물체 이미지들이다. Target Domain은 실제 가정에서 촬영된 듯한 리뷰 느낌의 이미지다.
사진의 스타일, 또는 배경 때문에 서로 의 분포가 다르겠지만, 레이블을 형성하는 곡면(outcome function)은 같다. 즉 같은 가 주어졌을 때 도 같을 것이다. ( 가 같다! )
그러나 왼쪽의 데이터만 가지고 학습을 했을 때, 오른쪽의 사진을 받아도 레이블을 잘 구별할 수 있을 거란 보장은 없다! 아마 잘 못 할 것이다..ㅎㅎ
그러면 Source Domain에서 학습한 정보를 가지고 어떻게 Target Domain으로 전이할 수 있을까? 대표적인 몇 가지 방법이 있는데, 다음 장에서 살펴보도록 하자.